Objet : Developers list for StarPU
Archives de la liste
- From: David <dstrelak@cnb.csic.es>
- To: starpu-devel@inria.fr
- Cc: Jiri Filipovic <fila@ics.muni.cz>
- Subject: [starpu-devel] Suspicious behavior of StarPU dmdar scheduler
- Date: Wed, 9 Feb 2022 18:57:33 +0100
- Authentication-results: mail2-smtp-roc.national.inria.fr; spf=None smtp.pra=dstrelak@cnb.csic.es; spf=Pass smtp.mailfrom=dstrelak@cnb.csic.es; spf=None smtp.helo=postmaster@cel1.sgai.csic.es
- Ironport-sdr: np7xLXtX7Qy5wSccQTRs4aS/1Oyiueik6PMZ21pE/zM0Cvmldu37R4AY06YMPTUqrmg1zgGjdx s+f7YZ3QrOAxvIod9uMwTNXOJCecAXP7hHJhX2B9pwdQF184PPTPUGtriwM6jp98kQCRiSoCf9 fYGulUjjhpbC/0OwBv5iqMw4kQZW7+uv1gw4uOpw+hoK8GSXpQrPgxCJ6bmVUZ2w++MdGT/Tw9 5/sqPoGBSZ0Uzt3A6e2edg419aeGCakUsoJssdIvH7rU9+7Oye5wVU1obct4VHJDmdk1Kvind8 4GbjhDSl17yuJfH2ubXO1SCW
- Ironport-sdr: kYNEU6lp80OntbOmPusor+f5CFYzuy1FvggLsI853JU/ml3ClXXwf+DhSd4cmv8eT6nsv4acaq 7c4+uh9JlsgJyyVPwhZtNjAMs5FU9q3zBeUceimlfRal4R6YhljD2PnZVHSlLnDe9qUog56CQa OniyjZU7g7znjogHC3BVcm9Z1p/22nUVLeJ9FvZcUO6AQWb6nqJDBMTs2cSNzD7Aj4rjmF9OgX 8l/JiECa3fgpCXIRgUIEt+Yct1m7n+TcMG0AjhO+qqzwJOQLpeBBVzeA0j7BDYok8RNWbw9g1q CYQ=
Dear StarPU team,
we are currently working on a research project which includes StarPU, and we have noticed some strange behavior, which we are not sure how to interpret and deal with.
It would be great if you can spend some time and have a look at the problem we're facing, and help us to determine if we don't work properly with StarPU, or there's some other problem.
We have designed a program that uses several algorithms, and we have provided both single-threaded CPU and CUDA implementation for each algorithm.
In a nutshell, this program creates 2D images and converts them to Fourier space where they are cropped.
After that, the correlation between each pair of images is computed, i.e. images are multiplied and then converted back from the Fourier space.
Finally, the resulting correlation data is searched for location of the maxima.
Notice that the images for the Forward Fourier Transformation are much bigger (4x) than those used for the Inverse Fourier Transformation.
Our algorithms are fully deterministic, i.e. program generates the same input and produces the same output on each invocation.
The program is PCI-e bound, i.e. the data transfer time is one of the crucial parameters which has to be taken into account by the scheduler.
At the level of the program, we run 10 iterations of the same work.
Before each test, we remove the existing performance models by deleting the '~/.starpu/sampling/codelets/' folder.
We run each test several times to create fresh performance models before the actual measurements we present below.
We tried all schedulers which are provided by StarPU by default and profiled the fastest one - dmdar.
We have noticed strange behavior in respect of the used resources and consequently the total execution time.
To benchmark our program, we use a machine with AMD EPYC (24 cores), two RTX 3090 (the 24GB versions), and 64GB of DDR4 memory.
1. use case: single GPU, no CPU (oneGPUnoCPU):
expected behavior: the GPU will be fully utilized, memory transfers will be done asynchronously, synchronization done at the end of each inner iteration
execution time: 7.2s
single average iteration: ~364ms
actual behavior: matches expectations
2. use case: use both GPUs, no CPU (twoGPUnoCPU):
expected behavior: both GPUs will be more or less equally utilized for the forward FT and crop, then share data for the correlation. Total execution time should be less than in case 1, but more than half of it.
execution time: 7.6s
single average iteration: ~365ms
actual behavior: Execution time is slower than expected. The first GPU is fully utilized by performing the memory transfers of the images, forward FT and crop, while the second one is used for the correlation and inverse FT.
This leads to the under-utilization of the second GPU, as it waits for the data computed on the first GPU.
3. use case: use all available resources (twoGPUallCPU):
expected behavior: most of the computation will be done on GPUs, as the CPU implementations are slower. Both GPUs should be more or less equally utilized. Total execution time should be less than in case 1, ideally less than half of it.
execution time: 8.0s
single average iteration: ~365ms
actual behavior: the majority of the work distributed to GPUs, CPUs get from 5 - 18 tasks (out of roughly 2500). Execution is not faster than in case 2.
4. use case: use only CPU (noGPUallCPU):
expected behavior: each CPU worker will be more or less equally utilized. Total runtime probably higher than in case 1.
execution time: 36,9s
single average iteration: ~3s
actual behavior: as expected. The bottleneck is in the first FT, which takes over 1/3 of the total per-iteration time. Other workers are waiting for work to do. Long task execution explains why GPU implementation is preferred in case 3.
5. use case: single GPU, all CPU (oneGPUallCPU):
expected behavior: some CPU workers will be utilized, but GPU should be preferred. Total runtime shorter or up to case 1.
execution time: 10.9s
single average iteration: ~575ms
actual behavior: GPU is being preferred for the forward FT. Then at least some data is transferred back to the CPU for correlation. Once all forward FT are computed, data is migrated again to GPU for inverse FT and the maxima search. This leads to prolonged computation.
Notice that we do not always reproduce this case. If we remove the performance metrics and run the test case again, sometimes we do not see this behavior, i.e. sometimes the scheduler decides not to execute tasks on CPU at all or not at presented scale.
Our questions are:
1. Do you think that the dmdar scheduler is not able to correctly take into account memory transfers, and thus under-utilizes GPU 2 in case 2 and case 3, and causes prolonged computation in case 5?
2. How can we verify that it is the scheduler to be blamed, and not some problem in our code?
3. Does StarPU try to transfer data between multiple GPUs in parallel? It seems that only one memory transfer is performed at the time, even though some motherboards support parallel communication at full speed (we're having a look if our MB supports it).
I attach traces for Vite and screenshots from Nsight Systems showing one internal iteration for each use case.
If you're interested, we can plan a video call where we can show you everything, or we can give you access to our test machine. Currently, the code is not public.
Thanks in advance.
KR,
David Strelak
Attachment:
noGPUallCPU.png
Description: PNG image
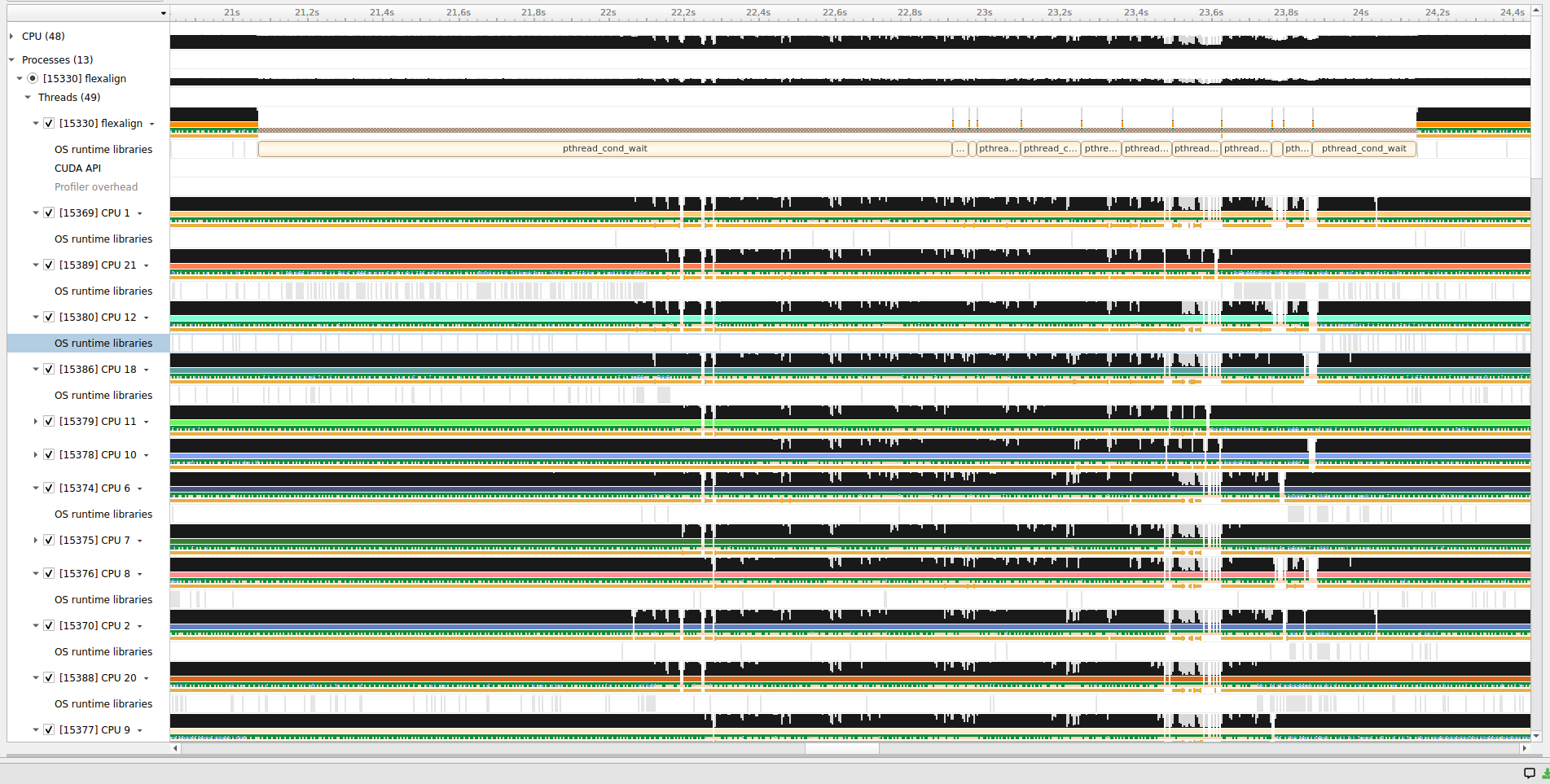{kind=link}
Attachment:
twoGPUallCPU.png
Description: PNG image
{kind=link}
Attachment:
oneGPUnoCPU.png
Description: PNG image
{kind=link}
Attachment:
twoGPUnoCPU.png
Description: PNG image
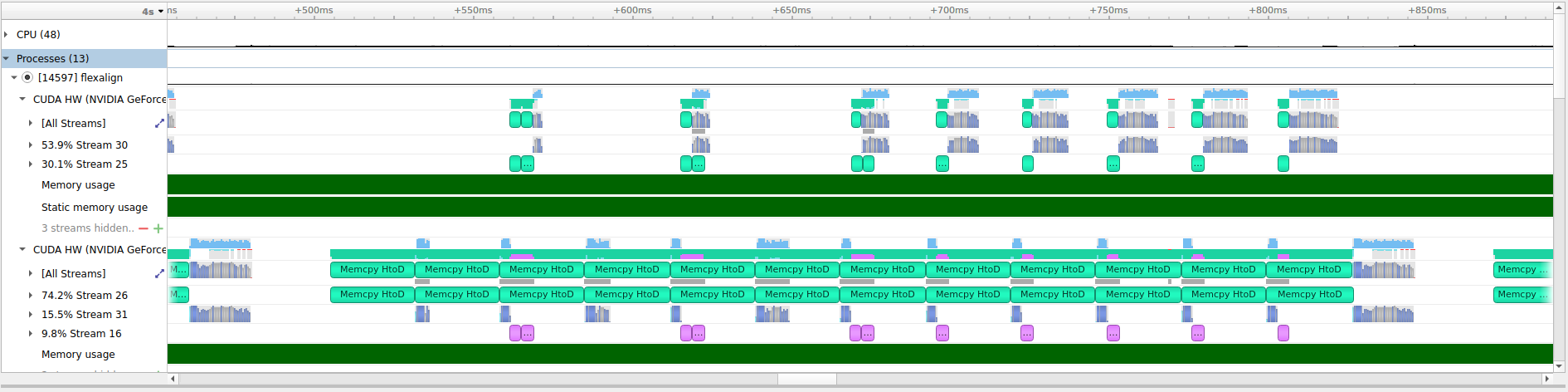{kind=link}
Attachment:
oneGPUallCPU.png
Description: PNG image
{kind=link}
Attachment:
traces.zip
Description: Zip archive
- [starpu-devel] Suspicious behavior of StarPU dmdar scheduler, David, 09/02/2022
- Re: [starpu-devel] Suspicious behavior of StarPU dmdar scheduler, Samuel Thibault, 21/02/2022
- Re: [starpu-devel] Suspicious behavior of StarPU dmdar scheduler, David, 23/02/2022
- Re: [starpu-devel] Suspicious behavior of StarPU dmdar scheduler, Samuel Thibault, 21/02/2022
Archives gérées par MHonArc 2.6.19+.